There's been a bit of a surge in feedback about ImageMapster in the last few weeks, which is fantastic because it means people have been using it. At the same time, it has made me acutely aware of the complexities of writing software that attempts to abstract a difficult problem into a general-purpose solution.
The problem I'm trying to solve is simple. Take an image. Create some rules about what happens when the user interacts with it. That's not that hard. They did it with Pong in 1972. Of course, Pong only had to work on one platform. Actually, the platform it worked on was designed only for pong.
My problem is a little more complicated. This plugin has to work on a whole bunch of different web browsers. Each of these browsers has a whole bunch of different versions.
In modern browsers, the software uses the HTML5 <canvas> feature to create its effects. HTML5 is an emerging specification. While this particular feature is well defined and has been available in common browsers longer than most, it's also one of the more sophisticated capabilities of a browser. It's like having your very own mini-Photoshop running in a browser. You can really do all kinds of crazy stuff.
Imagine if two different companies were trying to create Adobe Photoshop from a set of specifications. What are the chances that they would work the same way? With web browsers, though, it's about a half-dozen completely independent code bases.
Of course, canvases aren't nearly as complicated as a full design package, but there's still a lot of room for nuances. And since the spec is emerging, and has been implemented in various browser versions with varying degrees of success for a few years. Ideally, you want to code in such a way that avoids bugs that may exist in certain implementations.
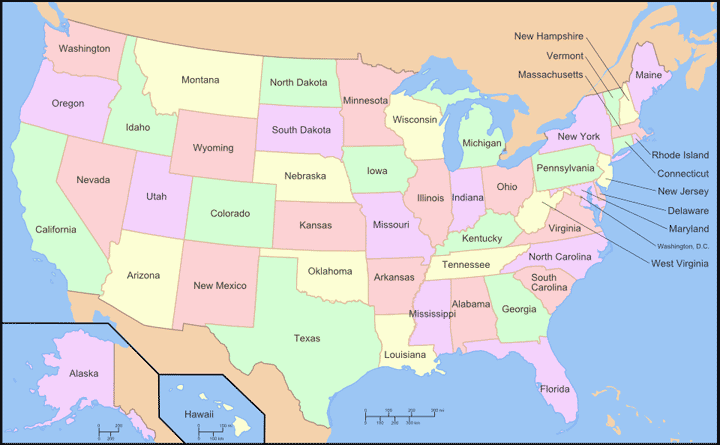
I recently fixed a bug that appeared with the release of Firefox 6. It had to do with masks. One of the features of ImageMapster is the ability to create hotspots in images, but also create an exclusion area. In the picture at left, the circle in the middle of Texas is a mask. (Technically, Texas is the mask, since it allows the hole to show through, but I thought it would be awkward to refer to the transparent areas as "holes"). In this configuration when someone mouses over Texas, the area in the middle will not get highlighted. If they move the mouse into the mask area, the highlight disappears.
Anyway, after substantively changing the approach used to create the masks to get around the problem with Firefox 6, I found that masks no longer worked in Firefox 3.6!
In old Firefox canvas implementations, there appears to be a problem when using globalCompositeOperation = "source-out" -- a critical feature for rendering masks - to make successive copies of canvases. That is, to create the effect, I would render all the "holes" on one canvas, then render that onto a canvas with the highlighted effect with "source-out", causing the holes to be excluded. Finally, though, I need to render those onto a third canvas (the one that gets displayed) which contains other highlighted effects. Somehow, this three step process completely fails in older Firefoxes.
Previously, I had achieved the effect with a simpler, two-step process. I render all the masks onto a canvas. Then, on the same canvas, I set "source-out" and render the highlighted effect. This works on every browser, except Firefox versions later than 6, which for some reason would do nothing with the masks.
I still haven't managed to isolate the exact nuances of the different behavior in different Firefoxes, because it involves many different actions in sequence on a canvas: paths, clipping, fills, context states, and so on. But suffice it to say, if I want this to work on all known versions of FF (and versions 4 and lower are still not uncommon), I will need two entirely different code paths for this feature.
Then, of course, there's VML, the vector markup language used by Internet Explorer prior to version 9. This is completely different again. In some ways, though, it's refreshingly simple. It works. It doesn't do everything that canvases do, but at least the implementation is consistent across all browsers that use it (that is, Microsoft), and at least it will never change again.
And finally, there's Apple computers. I test this thing on an iPad regularly. I don't own a Apple computer, though. My assumption has been, if it works on Windows Safari, and it works on my iPad, it's probably got a pretty darn good chance of working on apple Safari. I mean, they're all webkit in the first place, and you'd figure that a mobile touch screen device is a pretty good stress test for this kind of software.
No such luck. I got a user reporting no go on his mac this week. Then, another user tells me it doesn't work in chrome of all things! Chrome is what I use 90% of the time. I might forget to run tests in Firefox 3.6 but I never would push something that was broken in chrome. What is going on here? Well, most likely, it's something outside of ImageMapster: a local configuration issue. A firewall problem blocking images fetched with javascript, possibly due to CORS restrictions. But it's hard to troubleshoot, and as far as someone trying to use this can tell, it's just broken.
So what is the point? All this comes down to the whole point of this in the first place. Writing software that does complicated things on the Web and works for (almost) everyone is hard. But if it doesn't work for almost everyone, it's also useless. At the end of the day, it has to work. And this is the real reason why the next generation of the web's evolution has been slow. HTML5 canvases have been in Firefox, Chrome, and Opera for several years now. Yet, few web sites use these features. The big reason is because Internet Explorer versions older than 9 still have a substantial market share, and few people want to try to accomplish such things using VML. But another reason is that the implementations remain inconsistent across browsers, and it's difficult troubleshoot because not that many people are doing it. There's just not that much information out there about these nuances.
But to pass on it entirely because of these problems is to remain stuck in the last decade. There's tremendous power in the modern web browser. I mean, you can play angry birds right in your browser!
That makes my plugin look like child's play. Of course, they make no bones about it working in anything other than Chrome. (It supposedly works in Firefox too, but isn't really fast enough). The future is here - it just waits on the developers to embrace it, warts and all.